- pytorch로 VGG-16 모델을 구현하다가 softmax와 Negative Log-Likelihood의 용어를 알게되어서 정리해본다.
1. Softmax
- softmax는 보통 뉴럴 네트워크의 출력 layer에 속해있고 사용 목적으로는 multi-class classification과 같은 문제에서 최종 출력을 0과 1 사이의 확률값을 나타내기 위해 사용된다.
- 0~1 사이의 값으로 모두 정규화된 값으로 출력되고 출력값들의 총합은 항상 1이 되는 특징을 가지고 있다.
- 가장 큰 출력 값으로 부여받은 클래스가 확률이 가장 높은 것으로 사용된다.
pj=ezj∑kk=1ezj,j=1,2,3,...,k
zj = 소프트맥스 함수의 입력 값

- 소프트맥스 함수의 생김새는 "j번째 확률 / 전체 확률" 로 단순하게 볼 수 있다.
- 지수함수를 사용 하는 이유 ?
1. 양수화하여 미분이 가능하게 만들기 위해
2. 입력값 중 더 큰 값은 더 크게, 작은 값은 더 작게 만들어서 입력벡터를 더 잘 구분하기 위해
- 가운데 행렬이 출력값에 해당.
- 행렬의 첫번째 열은 고양이, 두번째 열은 개, 세번째 열은 말에 해당되며 가장 큰 값을 가지는 클래스가 선택이 된다.
- 첫번째 분홍색을 살펴보면 고양이가 5의 값으로 가장 크기때문에 고양이로 분류가 될 것이고, 두번째 파란색을 보면 가장 큰 8 값으로 출력된 말이 분류가 될 것이다.
- 세번째 초록색을 살펴보면 고양이와 개 값이 4로 같기 때문에 어떤 것을 선택해야할지 애매해진다.
- 마지막 행렬은 softmax 출력 결과에 해당.
- 가운데 행렬의 출력값으로 가장 큰 값을 출력해도 되지만 확률적으로 표현을 하면 더 직관적으로 살펴 볼수가 있다.
- 그래서 출력 마지막 layer에서 softmax를 사용하여 위 그림에서의 마지막 행력의 값으로 출력하게 만든다.
- softmax 연산은 대소 크기를 바꾸지 않기 때문에 앞에서(두번째 행렬)에서 선택된 것과 동일한 열이 선택된다.
- softmax의 출력은 뉴럴 네트워크의 confience와 같은 역할을 한다.
Sigmoid와의 차이점?
- Sigmoid는 출력 Layer의 값들을 보고, 0.5보다 크면 1, 작으면 0 이런식으로 이진분류 밖에 하지 못한다.
- Softmax는 출력 Layer로 나오는 모든 값들을 정규화(Normalizing)하고, 각각의 클래스에 대한 확률을 나타낸다.
2. Negative Log-Likelihood (NLL)
- softmax와 더불어서 NLL을 이용하여 딥러닝의 Loss를 만들 수 있다.
방법 1. argmax를 취하는 방법
- 입력에 대한 softmax 출력중 가장 큰 값을 다음 식에 적용하면 된다.
- y는 softmax 출력값 중 가장 큰 값이다.
L(y)=−log(y)
- log 함수와 음의 부호를 사용함으로써 softmax의 출력이 낮은 값은 -log(y) 값이 크도록 만들수 있고, softmax의 출력이 높은 값은 -log(y)의 값이 0에 가깝도록 만들어준다.
- 정답 클래스의 softmax 출력이 높은 값을 가질 경우, -log(y) 값은 매우 작아지게 된다. = Loss가 작아지는 것과 같다.
- 정답 클래스의 softmax 출력이 낮은 값을 가질 경우, -log(y) 값은 매우 커지게 된다. = Loss가 높아지는 것과 같다.
- 그래서 softmax 출력에 대한 -log(y)는 Loss처럼 나타낼 수 있다.
방법 2. 모든 logit에 적용하는 방법
- 모든 softmax 출력 logit에 대해 Loss를 구하는 방법이다.
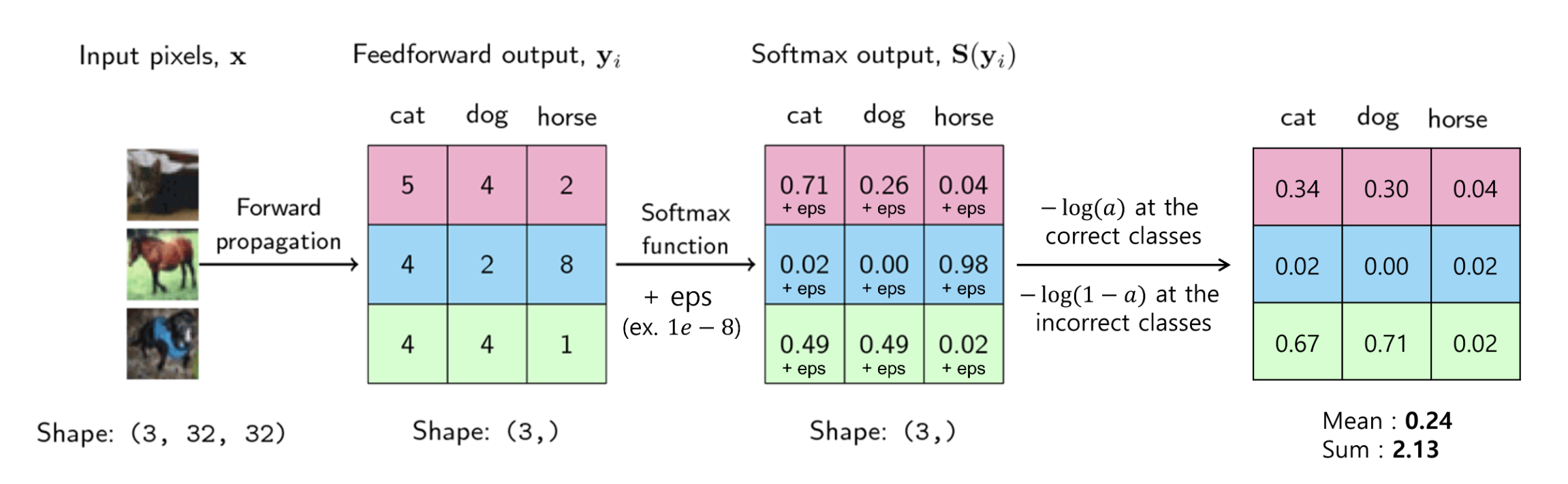
- 정답에 해당하는(softmax 결과값이 가장 큰) 경우, −log(a)를 취하고, 정답이 아닌 클래스에는 −log(1−a)를 취한다.
- 정답 클래스의 경우, softmax 결과가 1에 가까워지는데, 1에 가까워질수록 −log(a)는 0에 가까워진다. = Loss가 작아지는 것과 같다.
- 정답이 아닌 클래스의 경우, softmax 결과가 0에 가까워지는데 0에 가까워질수록 −log(1−a)는 0에 가까워진다. = Loss가 작아지는 것과 같다.
- 최종적으로 계산된 모든 "NLL Loss"에 대해 합 또는 평균을 취해보면 Loss가 하나의 스칼라 값으로 도출되게 된다.
- +eps(epsilon)을 하는 이유?
- epsilon : 임의의 매우 작은 양수를 의미
- 극단적으로 Loss 값이 무한대로 가까워져서 NaN이 생기는 것을 방지하기 위해
pytorch에서 사용되는 Loss 방법은 2번.모든 logit을 적용하는 방법이다.
참고 :https://gaussian37.github.io/dl-concept-nll_loss/#softmax-1
반응형
'Dev. > DL' 카테고리의 다른 글
| [HUCV] Human Pose Estimation4 - Mask R-CNN (0) | 2024.05.03 |
|---|---|
| [HUCV] Human Pose Estimation3 - 2D human pose estimation의 분류 (0) | 2024.04.30 |
| [학습 이슈] validation 정확도가 train 정확도보다 높은 경우 (1) | 2023.12.08 |
| [CV] Object Detection (0) | 2023.03.06 |
| [CV] Detectron2 모델 환경 설정 (0) | 2023.01.11 |

