이전에 Seq2Seq에 대한 한계점과 해결 방안인 Attention 기법 위주로 논문을 읽어 보았다.
2023.02.12 - [Review a paper] - [Transformer] Attention is all need(1) Seq2Seq 한계점
오늘은 트랜스포머 (Transformer)에 대해서 알아보고 핵심기능은 Attention 을 더 자세히 알아보고자 한다.
1. 트랜스포머(Transformer)란?
- 2021년 기준으로 현대의 자연어 처리 네트워크에서 핵심이 되는 논문이다.
- 논문의 원제목은 Attention Is All You Need이다.
- Attention 기능 하나만 잘 사용해도 NLP 분야에서 좋은 성능을 얻을 수 있다.
- 트랜스포머는 RNN이나 CNN을 전혀 필요로 하지 않는다는 특징이 있다.
- 대신, Positional Encoding을 사용한다. (이것은 RNN, CNN 대신 순서 정보를 제공하기 위함)
- BERT와 같이 향상된 네트워크에서도 채택되고 있다. (+ GPT도 마찬가지)
- Encoder(인코더), Decoder(디코더)로 구성이 되어있다.
- 둘 다, Attention 과정을 여러 레이어에서 반복한다.
Transformer Architecture

2. 트랜스포머의 동작 원리 : 입력 값 임베딩 (Embedding)
- 트랜스포머 이전의 전통적인 임베딩의 모습이다.
- 입력차원 자체는 언어에서 존재할 수 있는 단어의 갯수와 동일하다.
- 차원이 많을 뿐만 아니라, 대부분 원핫인코딩 형태로 표현되기 때문에 임베딩을 진행한다.
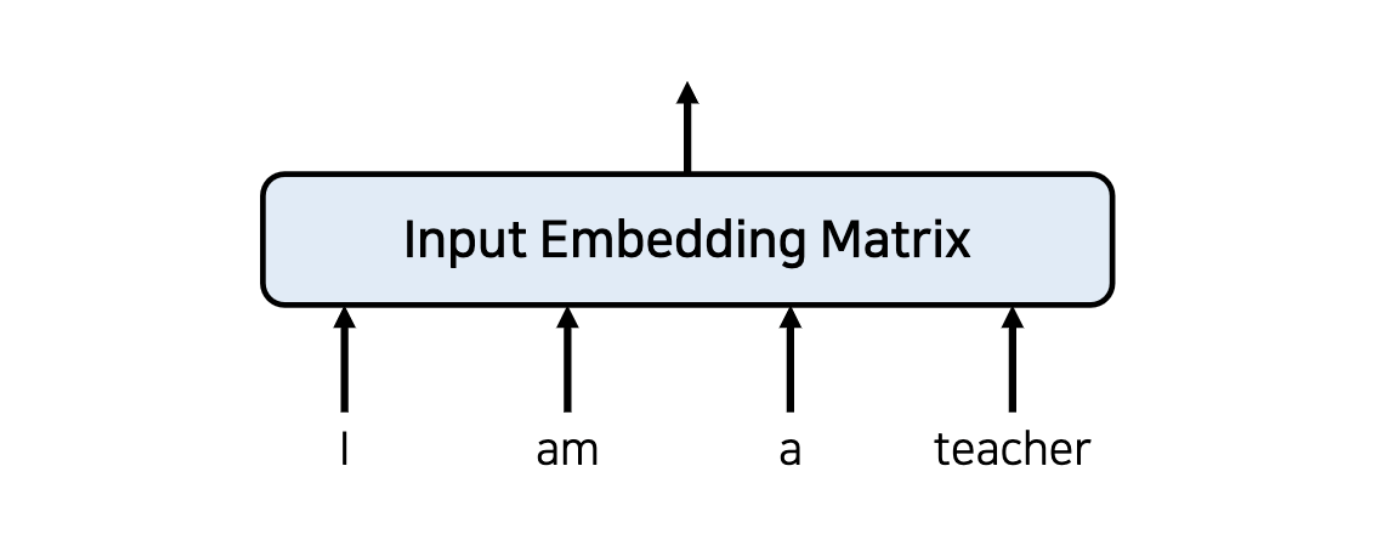
- RNN을 사용하지 않으려면 위치 정보를 포함하고 있는 임베딩을 사용해야한다.
- 이를 위해, 트랜스포머에서는 Positional Encoding을 사용한다.

3. 트랜스포머의 동작 원리 : 인코더(Encoder)
- 임베딩이 끝난 이후에 Attention을 진행한다.

- 여기서 Multi-head Attention이 Intput으로 받는 값은 "입력 문장에 대한 정보" + "실제 위치 정보" 이다.
- Encoder에 사용되는 Attention은 "Self Attention"이라고 부른다.
- Self-Attention ?
- 각각의 단어가 서로에게 어떤 연관성을 가지고 있는지 구하기 위해 사용 (Attention score를 계산)
- 한 문장에서 각 단어의 서로에 대해 연관성을 구하기 때문에 "문맥에 대한 정보를 학습"한다고 이해할 수 있다.
- 성능 향상을 위해 잔여학습(Residual Learning)을 사용한다.
- 잔여학습 : 이미지 분류 Resnet network에서 사용


- 어텐션 (Attention)과 정규화 (Normalization) 과정을 N번 반복한다.
- 각 레이어는 서로 다른 파라미터를 가진다.
- Input과 Output의 차원은 동일해야한다.
4. 트랜스포머의 동작 원리 : 인코더(Encoder)와 디코더(Decoder)

- 트랜스포머에서는 마지막 인코더 레이어 출력(output)이 모든 디코더 레이어에 입력(input)이 된다.
- 대부분 Encoder와 Decoder의 layer 수를 맞춰준다.

- 이때 RNN을 사용하지 않고 인코더와 디코더를 다수 사용한다는 점이 특징이다.
- <eos>가 나올때까지 디코더를 이용한다.

5. 트랜스포머의 동작 원리 : 어텐션 (Attention)
- 인코더와 디코더는 "Multi-Head Attention"레이어를 사용한다.
- 어텐션을 위한 세 가지 입력 요소
- 쿼리 (Query) : "물어보는 주체"
- 키 (Key)
- 값 (Value)
- EX) A단어가 B단어에 대해서 어떠한 가중치 값을 가지는지 구한다고 할 때, A단어가 Query가 되고, B단어가 Key가 된다.

- Multi-Head Attention
- V, K, Q가 들어오면, Linear Layer를 통해 행렬곱을 수행하여 head의 수(h)만큼 Attention 컨셉을 만들어서 다양하게 학습을 하고자 한다.
- Scaled Dot-Product Attention
- h (head 개수) : 서로 다른 입력 문장이 들어왔을 때 V, Q, K로 서로 구분되는데, 이 때 h개의 서로 다른 V, Q,K 로 구분되도록 만들어준다.

- Attention 계산식에서는 softmax 함수를 사용한다.
- softmax "n"개의 다른 이벤트에 대해 이벤트의 확률 분포를 계산해주는 함수이다.
- softmax를 사용하면, 0 근처의 위치에서는 gradient가 높게 형성되지만, 값이 계속 이동하게 되면 기울기 값이 줄어들게 되어 Gradient vanishing (기울기 손실)문제가 발생하게 된다.
- Gradient vanishing 문제를 해결하기 위해서, √d_k(key dimension) 으로 값을 나눠준다.
- 서로 다른 linear layer를 통해 h(head 개수)개의 K, Q, V를 생성해준다.
- 이후 , Concat으로 Output 차원을 Input 차원과 맞춰준다.
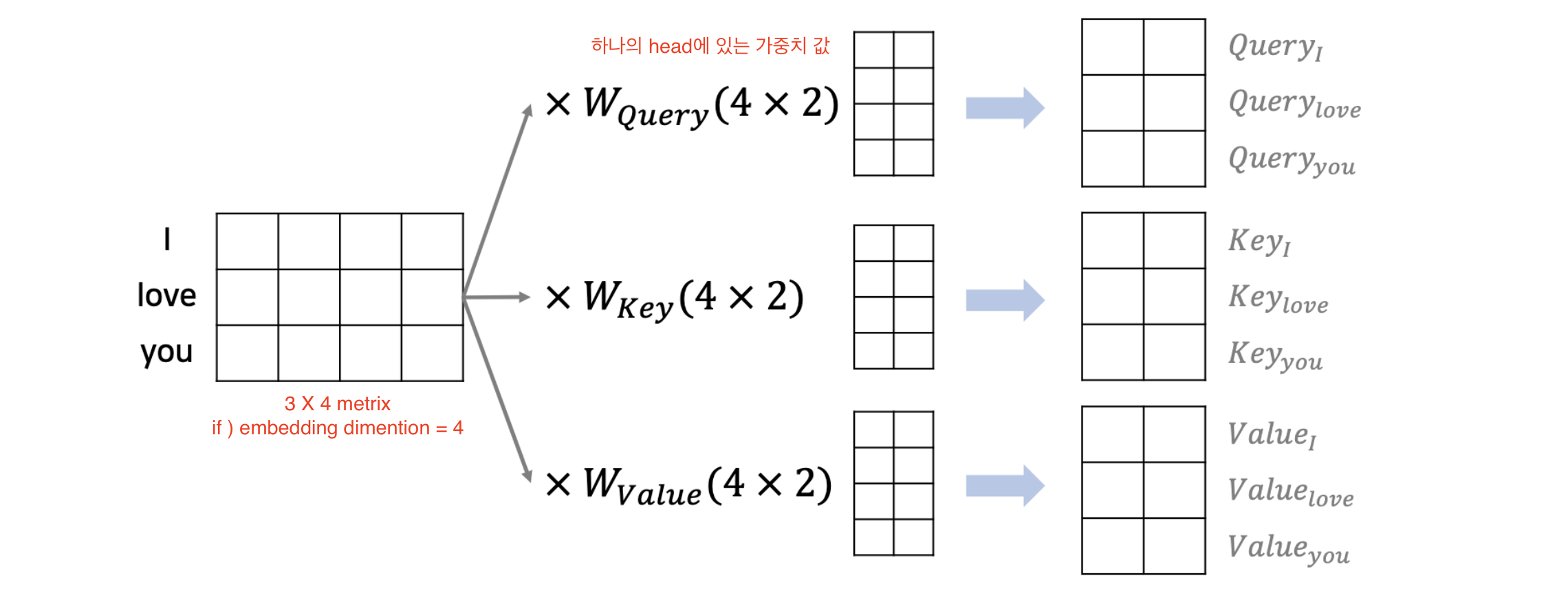
6. 트랜스포머의 동작 원리 (하나의 단어) : 쿼리(Query), 키(Key), 값(Value)
- 어텐션을 위해 각각의 head 마다 쿼리(Query), 키(key), 값(Value)이 필요한다.
- 각 단어의 임베딩(Embedding)을 이용해 생성할 수 있다.

- EX1 ) d_model = 512차원이고 head 개수가 8개일 경우, 512 / 8 = 64개의 Q, K, V가 생기게 된다.

- 실제로는 행렬(matrix) 곱셈 연산을 이용해 한꺼번에 연산이 가능하다.
7. 트랜스포머의 동작 원리 (행렬) : Scaled Dot- Product Attention

- 마스크 행렬(mask matrix)를 이용해 특정 단어는 무시할 수 있도록 한다.
- 마스크 값으로 음수 무한의 값을 넣어 softmax 함수의 출력이 0%에 가까워지도록 한다.
8. 트랜스포머의 동작 원리 : Multi-Head Attention
- MultiHead(Q,K,V)를 수행한 뒤에도 차원(dimension)이 동일하게 유지된다.

9. 트랜스포머의 동작 원리 : 어텐션(Attention)의 종류
- 트랜스포머에서는 세 가지 종류의 어텐션(attention) 레이어가 사용된다.
- Encoder Self-Attention : 하나의 문장에서 각 단어들끼리의 유사성을 계산한다. (문맥 파악용)
- Masked Decoder Self-Attention : 앞쪽에 등장한 차원들만 고려할 수 있도록 mask를 씌워준다.
- Encoder-Decoder Attention : Query(decoder행렬)와 Key, Value (encoder행렬)를 비교해서 attention score을 구해준다.

10. 트랜스포머의 동작 원리 : Self-Attention
- Self-Attention 은 인코더와 디코더 모두에서 사용된다.
- 매번 입력 문장에서 각 단어가 다른 어떤 단어와 연관성이 높은 지 계산할 수 있다.
11. 트랜스포머의 동작 원리 : Positional Encoding
- Positional Encoding은 다음과 같이 주기 함수를 활용한 공식을 사용한다.
- 각 단어의 상대적인 위치 정보를 네트워크에게 입력한다.

Reference
- 나동빈님의 'Transformer : Attention Is All You Need' 논문 리뷰 영상
https://www.youtube.com/watch?v=AA621UofTUA
반응형
'Review a paper' 카테고리의 다른 글
| [LLaVA] LLaVA : Large Language and Vision Assistant (0) | 2025.02.23 |
|---|---|
| [Sketch rnn] A Neural Representation of Sketch Drawings (0) | 2023.04.25 |
| [Transformer] Attention is all need(1) Seq2Seq 한계점 (0) | 2023.02.12 |


